Processing 100 million lines of LEHD data.
March 27, 2018
March 27, 2018
Census blocks, at a national level are a pretty challenging size of data to work with. There are about 7.7 million census blocks in the country and tasks can quickly become too intensive to process all at once. In this post I want to walk through some solutions I found when working with LEHD (Longitudinal Employer-Household Dynamics) data from U.S. Census.
the goal of my current project is to evaluate the commercial corridors across the top 100 MSAs in the U.S. To identify these areas, I filtered census blocks with retail jobs along primary roads and narrowed down a set that represents a sample of commercial corridors. My aim is to start at the census block level and aggregate from there to more general levels of geography.
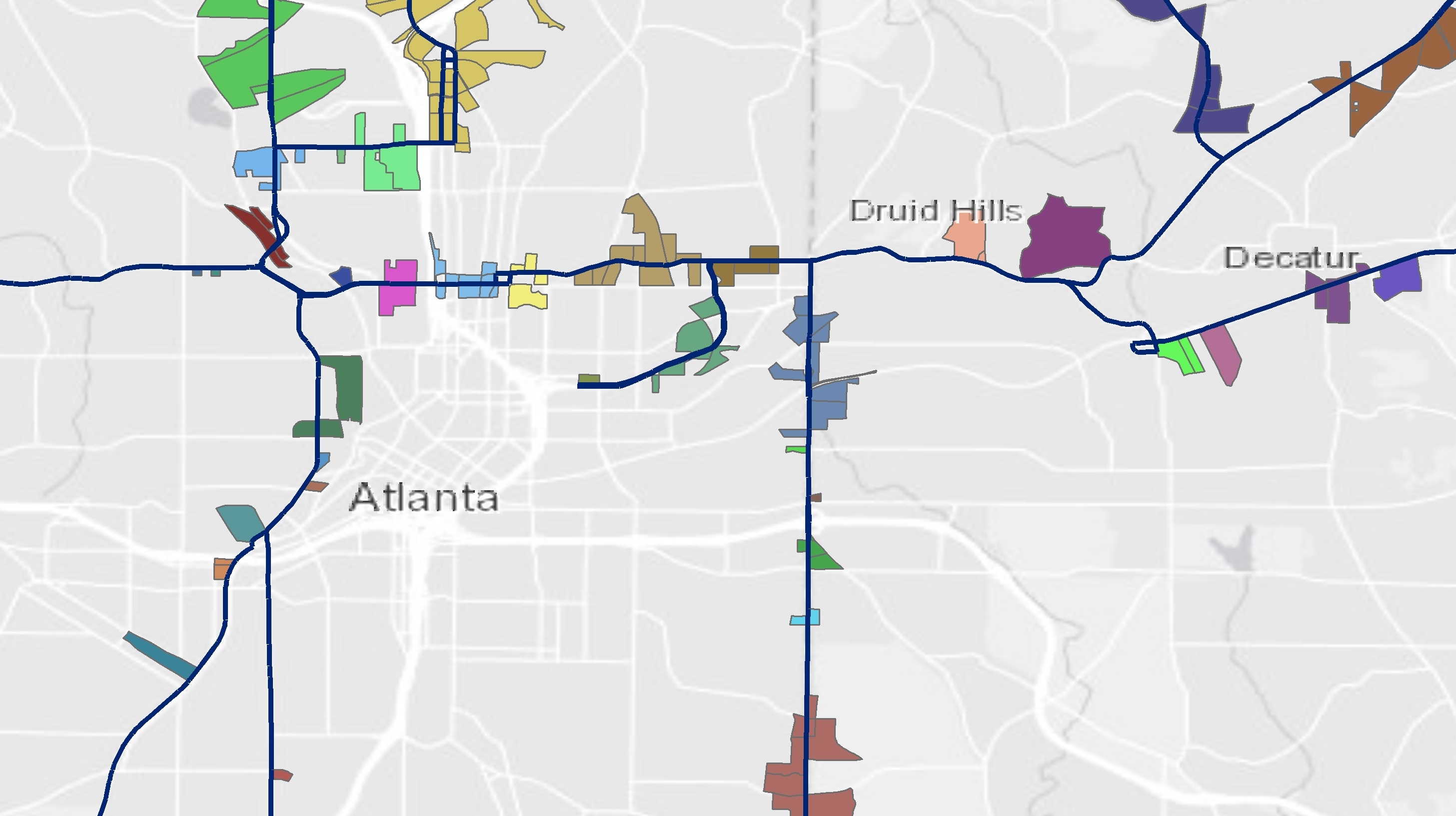
Below is a rough screenshot of some of the corridor areas that I will be working with as my sample:
To get all of the OD trips that have the same home and work geocode first at the block level (and later at the block group level). I broke down the code needed in R to process the following tasks:
- read all 51 Origin and Destination files for each state
- edit the home and work geoid’s cutting off the block so that they are at the block group level
- subset the files for just those where the home and work locations match
- perform an inner join with the set if GIS files I’ve created
- aggregate the total trips from blocks to the block group level
Luckily for this project I already had some thoroughly commented code developed from a previous project that was fairly similar. My first challenge was to easily download all of the LEHD files. There are 51 files for all of the states and I need them from two datasets doubling the total count. I found a tool Seamless-census that is a great Python command that will download data for all states using the US Census’s FTP site. I forked this repo over to my GitHub account and made some edits to the code to grab OD data as well.
In GIS, I used the NHGIS website to quickly download all of the block shapefiles. From there I paired down the total number of blocks from 7.7 million to just about 45,000. (After processing all of the raw LEHD data in R, I will use an inner join to filter it down to those that match with my GIS files.)
The LEHD data totaled about 100 million lines when combined but I could read and process each file if needed. So my plan was to loop through each and add the reduced results to a single data frame. The results should be small enough to be handled together in later steps.
Finally, I wanted to find all of the trips made within “the same neighborhood.” In my first go through, I used the code(lapply()) method in R to loop through and find trips within the same census block.
setwd("SET YOUR FILEPATH HERE")
#Gather a list of all the files needed to process.
temp = list.files(pattern="*.csv")
#lapply basically applies the following code to each file in the list (temp):
# read in the csv and subset according to the two geocode columns
#rbind adds the results to a common data frame after lapply finishes each file
myfiles = do.call(rbind, lapply(temp, function(x)
subset(read.csv(x, stringsAsFactors = FALSE), w_geocode==h_geocode)))
However, a census block is a little too small. This dataset was better than nothing, but I really wanted to add a little extra steps to the processing and try to get trips within the same block group. The block group level does a little better to represent trips “within the same neighborhood” within the data I had available from the census. As a result of this, I wanted to add a few extra steps to my process. Mostly I wanted to adjust the two geocode columns and remove the last three digits to aggregate these results to the census block level (12 characters) before creating a subset of the matching values. I changed up the code from using code(lapply()) and instead used a loop syntax that I find easier whenever I want to add in a few extra steps as needed.
The code below does basically the same task as that shown above, but with a few extra tasks added:
setwd("SET YOUR FILEPATH HERE")
#Gather a list of all the files in the workspace needed to process.
temp = list.files(pattern="*.csv")
#set up an empty data frame that the loop can add the results to.
df_total = data.frame()
for(i in 1:length(temp)){
dat = read.csv(temp[i],header=TRUE, colClasses=c("w_geocode"="character", "h_geocode"="character"))
print(temp[i])
#The trips are at block level. Curtting off the suffix to get block group GEOID
dat$w_geocode <- as.character(str_sub(dat$w_geocode, 1, 12))
dat$h_geocode <- as.character(str_sub(dat$h_geocode, 1, 12))
#Limiting the dataset just to the data needed.
dat <- dat[c("w_geocode", "h_geocode", "S000")]
dat <- subset(dat, w_geocode==h_geocode)
df_total <- rbind(df_total,dat)
}
# Aggregating results from block to BG level
df_total <-aggregate(S000 ~ w_geocode, df_total, FUN=sum)
rm(temp, i)
So now everything is filtered summarized at the block group level. Now I have a managable subset that I can filter even further to my selected corridors with an inner join.
I look forward to sharing the results of this project once the report is released!